Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM

In the world of data handling and exchange, JSON (JavaScript Object Notation) has become a prevalent format. Its simplicity and readability make it a favorite for developers. However, as data grows in complexity, ensuring a clean and efficient JSON structure becomes crucial. This article explores effective strategies for JSON cleanup techniques to enhance data quality and performance.
To clean up JSON data effectively, one must first understand its structure. JSON is composed of key-value pairs, similar to a dictionary in Python or an object in JavaScript. This format allows for easy nesting, where values can be other JSON objects or arrays.
Understanding these characteristics is the first step in identifying potential issues and areas for cleanup within your JSON data. A well-structured JSON not only facilitates easy data exchange but also minimizes the risk of errors during data processing. By grasping the nature of JSON, developers can design data models that are both efficient and maintainable.
JSON is widely used in web development, particularly in API responses and configurations. It is the de facto format for RESTful APIs, where it helps in transmitting data between client and server. JSON’s lightweight nature makes it suitable for mobile applications, where bandwidth and processing power are limited. By understanding these use cases, developers can appreciate the need for JSON cleanup to ensure optimal performance.
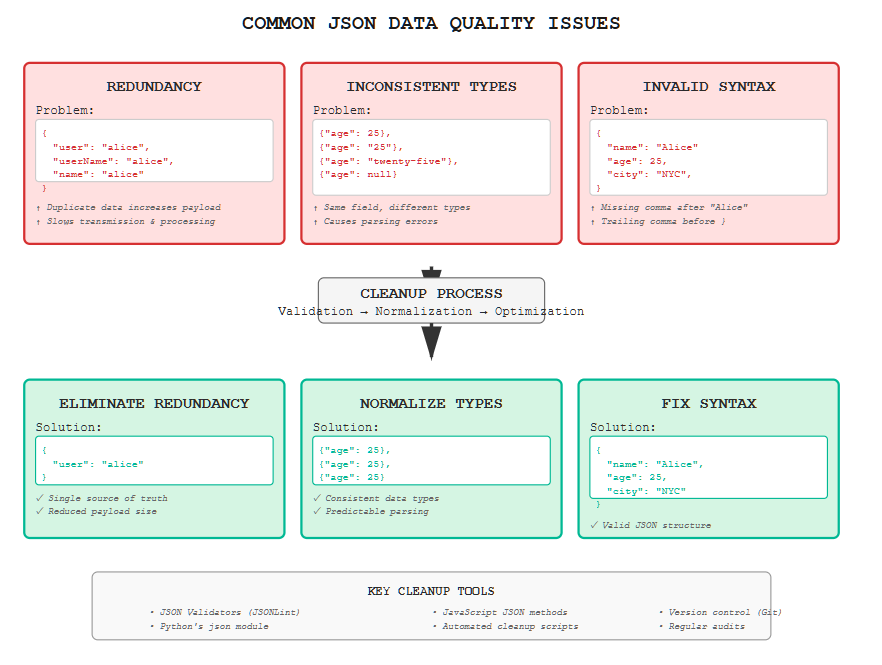
Before diving into cleanup techniques, it’s important to identify common issues that can arise in JSON data structures.
Redundant data can lead to increased payload sizes, which slows down data processing and transmission. Identifying and removing redundant elements is essential for optimizing JSON performance.
Redundant data increases the size of the JSON payload, which can slow down the transmission of data over networks. This is particularly problematic in applications where bandwidth is limited or where speed is critical. Redundant data can also complicate data parsing and analysis, leading to inefficiencies and errors.
To identify redundant data, developers should analyze their JSON structures to find duplicate records or fields that are no longer necessary. This can involve examining data usage patterns to determine which elements are truly needed for the application to function correctly.
Eliminating redundancy involves carefully reviewing the JSON data to remove unnecessary elements. This can involve restructuring the data model to reduce duplication or implementing algorithms that automatically filter out redundant data.
JSON is flexible, but this can lead to inconsistencies, such as mixed data types for the same field across different JSON objects. These inconsistencies can cause errors during data parsing and analysis.
Inconsistent data types can lead to significant issues during data processing. For instance, if a field is expected to be a number but is sometimes a string, it can cause type errors in applications that consume the JSON data. This can result in crashes or incorrect data interpretation.
To detect inconsistencies, developers can use validation tools that check for type mismatches across JSON data. Regular audits of the data can also help in identifying fields where type inconsistencies are prevalent.
Ensuring data type consistency involves standardizing the format of each field across all records. This might involve converting all instances of a date field to a uniform string format or ensuring numerical fields do not contain string representations.
JSON syntax errors, such as missing commas or misaligned brackets, can lead to parsing failures. Ensuring syntactical correctness is a fundamental part of JSON cleanup.
Syntax errors are common in JSON due to its strict format requirements. Missing commas between key-value pairs or incorrect bracket placements can render JSON data invalid, leading to parsing errors.
Using JSON validators can help in quickly identifying syntax errors. These tools provide detailed error messages that point to the exact location of the error, making it easier for developers to correct them.
To avoid syntax errors, developers should adhere to best practices such as using tools that auto-format JSON data, employing code editors with syntax highlighting, and integrating JSON validation into their development workflow.
Implementing effective JSON cleanup techniques can significantly enhance data quality and performance. Below are some strategies to consider:
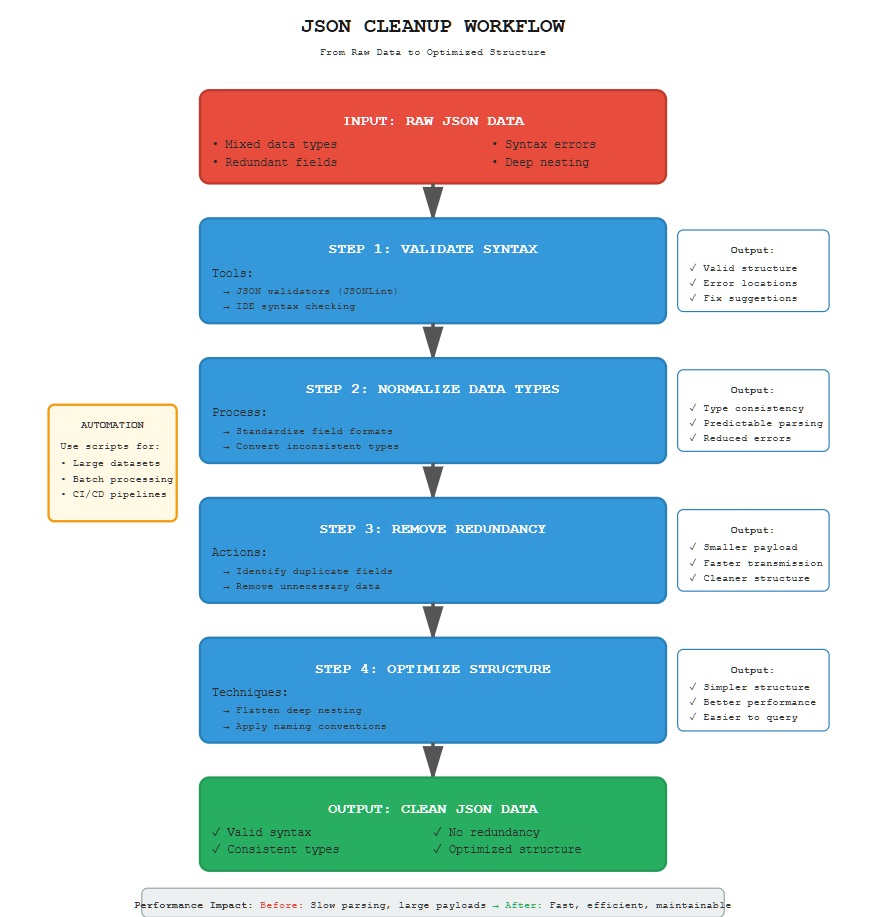
A JSON validator is a tool that checks JSON data for syntax errors. By using a validator, you can quickly identify and correct issues in your JSON structure, ensuring it is well-formed and ready for processing.
Validators help ensure that JSON data is syntactically correct, reducing the likelihood of errors during data processing. They provide immediate feedback, allowing developers to address issues early in the development cycle.
There are numerous JSON validators available, both online and as part of development environments. Tools like JSONLint and built-in IDE features can offer real-time validation and error detection.
To maximize the benefits of JSON validation, developers should integrate validation checks into their build processes. This can involve setting up automated tests that run validators on JSON data as part of continuous integration pipelines.
To avoid inconsistencies, it’s crucial to normalize data types within your JSON structure. For example, ensure that a field representing a date is consistently formatted as a string or a date object across all records.
Normalization ensures that data is processed correctly by applications, preventing type errors and ensuring consistent application behavior. It also simplifies data transformations and analytics.
Normalization can involve setting standards for each data type and applying these consistently across all JSON records. Tools and scripts can automate the process, converting fields to the desired format as data is ingested.
While normalization is beneficial, it can be challenging to enforce consistently, especially in environments with multiple data sources. Regular audits and automated checks can help maintain consistency.
Carefully review your JSON data to identify and remove redundant elements. This might include duplicate records or unnecessary fields that do not contribute to your data processing goals.
Identifying redundant data involves analyzing JSON structures to pinpoint unnecessary repetitions or obsolete fields. Data usage analytics can highlight fields that are rarely or never used.
Strategies for removing redundant data include refactoring JSON structures to eliminate duplicate fields and implementing deduplication algorithms that automatically filter out unnecessary elements.
Removing redundant data can lead to significant improvements in data processing speed and efficiency. It also reduces storage costs and simplifies data management.

While JSON’s ability to nest objects and arrays is powerful, overly complex nesting can complicate data processing. Flattening these structures where possible can simplify data handling and improve performance.
Flattening structures is beneficial when nested data becomes difficult to manage or hinders performance. It is particularly useful when preparing data for analysis or transformation.
Flattening techniques involve restructuring JSON data to minimize nesting levels. This can be done manually or using tools and scripts that automate the process, ensuring data remains accessible and manageable.
While flattening can simplify data, it is important to ensure that it does not lead to loss of essential hierarchical relationships. Developers should carefully balance simplicity with data integrity.
For large datasets, manual cleanup is impractical. Automating the cleanup process with scripts can save time and reduce errors. Use programming languages like Python or JavaScript to write scripts that parse and clean your JSON data efficiently.
Automation allows for consistent and repeatable cleanup processes, reducing the potential for human error. It also speeds up the cleanup process, making it feasible to handle large volumes of JSON data.
Languages such as Python and JavaScript offer powerful libraries for JSON manipulation. Libraries like Python’s json module or JavaScript’s JSON methods can be used to write scripts that automate various cleanup tasks.
Integrating automated cleanup scripts into workflows involves setting up regular scheduled tasks or triggers that execute scripts whenever new JSON data is ingested. This ensures ongoing data quality without manual intervention.
Several tools and libraries are available to assist with JSON parsing and cleanup. Here are a few popular ones:
Python’s built-in json module offers functions for parsing JSON data and writing cleaned JSON objects. It is a powerful tool for automating JSON cleanup tasks.
The json module provides methods for serializing and deserializing JSON data, making it easy to convert between JSON strings and Python objects. Its simplicity and integration with Python’s ecosystem make it a go-to choice for developers.
This module is particularly useful for processing JSON data in data science applications, web development, and automation scripts. It allows developers to manipulate JSON data efficiently within Python applications.
For more advanced JSON manipulation, Python offers additional libraries like jsonschema for validation and pandas for data analysis, which can complement the capabilities of the json module.
In JavaScript, JSON.parse() is used to convert JSON strings into objects, while JSON.stringify() can serialize objects back into JSON strings. These functions are essential for manipulating JSON data within web applications.
These functions are fundamental to JSON handling in JavaScript, allowing developers to convert between JSON strings and JavaScript objects seamlessly. They enable dynamic data manipulation in web applications.
JSON.parse() and JSON.stringify() are commonly used in AJAX requests, local storage operations, and data interchange between client and server. They facilitate real-time data processing and storage in web applications.
Modern JavaScript frameworks and libraries offer enhanced JSON handling capabilities, building on these core functions. Developers can leverage frameworks like React and Angular to manage JSON data more efficiently.
There are numerous online tools available for JSON validation, formatting, and cleanup. Websites like JSONLint provide easy-to-use interfaces for checking JSON syntax and structure.
Online tools offer quick and accessible solutions for JSON validation and formatting without needing to install software. They are particularly useful for developers needing immediate feedback on small JSON snippets.
Tools like JSONLint and JSON Editor Online provide features for syntax checking, formatting, and even collaborative editing. They are widely used for quick fixes and prototyping.
Developers can integrate online tools into their development workflow by using browser extensions or APIs that allow for automated validation and formatting within development environments.
To maintain clean and efficient JSON data, consider the following best practices:
Use consistent naming conventions for keys to avoid confusion and ensure ease of access. Consistency in naming helps in maintaining clarity and reduces errors in data processing.
Consistent naming conventions improve code readability and maintainability. They help developers quickly understand data structures and facilitate seamless collaboration in team environments.
Adopt industry-standard naming conventions such as camelCase or snake_case and apply them uniformly across all JSON data. Document these conventions to ensure team-wide adherence.
Tools like linters and code formatters can automatically enforce naming conventions, ensuring that all JSON keys adhere to predefined standards. This reduces manual oversight and potential errors.
Periodically review your JSON data for errors and redundancies. Regular audits help in maintaining data quality and identifying issues before they escalate into larger problems.
Regular audits allow for early detection of errors, inconsistencies, and redundancies. They ensure that data remains accurate and reliable, supporting informed decision-making.
Use automated tools and scripts to conduct audits, focusing on areas prone to errors such as data types and syntax. Develop a schedule for regular reviews to ensure ongoing data integrity.
Auditing can be resource-intensive, especially for large datasets. Balancing thoroughness with efficiency requires a strategic approach, leveraging automation to streamline the process.
Use version control systems to track changes in your JSON data structures and revert to previous versions if necessary. Version control helps in managing changes and maintaining data history.
Version control provides a history of changes, enabling developers to track modifications and revert to earlier versions if errors are introduced. It supports collaborative development by merging changes from multiple contributors.
Implement version control systems like Git to manage JSON data, treating JSON files as code. This allows for branching, merging, and rollback, facilitating efficient data management.
Establish clear guidelines for versioning JSON data, including commit messages that describe changes and the rationale behind them. This documentation helps in understanding the evolution of data structures over time.
As AI continues to grow, it will offer multiple applications germane to helping you clean up your JSON. Tools like Claude and ChatGPT can already accomplish these tasks. We should never, however, forget the dangers of unchecked AI such as AI weaponization, AI specification gaming, and the false promise of AI alignment and ethical AI.



